Multi-Scale Parallelism in yt
bySamuel Skillman
Kavli Fellow, KIPAC/Stanford/SLAC
The communication_system
First off, mpi4py
Modelled as a hierarchy of (MPI) Communicators
Make it simple to pop communicators on/off a stack
Provide collective operations on Python dicts, numpy arrays, values
Allow Multiple Entries
- Simple, embarrasingly parallel tasks
- Automatic Parallelization of Common Tasks
- Dynamic Time-series Iterators
- Specifically Tuned Parallel Volume Rendering
Make Embarrasingly Parallel Work Stupidly Simple
all_objects = range[10]
for obj in parallel_objects(all_objects):
print rank, obj
% mpirun -np 4 python parallel_obj.py --parallel
yt : [INFO ] 2014-02-20 20:54:02,602 Global parallel computation enabled: 1 / 4
yt : [INFO ] 2014-02-20 20:54:02,602 Global parallel computation enabled: 3 / 4
yt : [INFO ] 2014-02-20 20:54:02,602 Global parallel computation enabled: 0 / 4
yt : [INFO ] 2014-02-20 20:54:02,604 Global parallel computation enabled: 2 / 4
1 1
1 5
1 9
2 2
2 6
3 3
3 7
0 0
0 4
0 8
Dynamic Load Balancing
num_i_did = 0
all_objects = range(10)
for obj in parallel_objects(all_objects, dynamic=True):
num_i_did += 1
time.sleep(np.random.random())
print rank, 'did', num_i_did
2 did 5
1 did 2
0 did 0
3 did 3
Collect results. Map-reduce, etc.
my_storage = {}
for sto, obj in parallel_objects(all_objects, storage=my_storage):
sto.result = "My sweet result %f" % np.random.random()
if rank == 0:
for k,v in my_storage.iteritems():
print k, v
0 My sweet result 0.740464
1 My sweet result 0.702325
2 My sweet result 0.426925
3 My sweet result 0.187383
4 My sweet result 0.416627
5 My sweet result 0.545196
6 My sweet result 0.495298
7 My sweet result 0.157545
8 My sweet result 0.426106
9 My sweet result 0.432309
Use Case (Nathan Goldbaum, UCSC): I've got a local cluster that sits empty half the time
Old Method:
Serial IDL scripts (only one license) to make 500 Frame movie. ~hours
New Method:
parallel_objects to farm out to empty cores on local cluster ~hours/N
Get Things Done
Statistical Quantities
TotalQuantity
AveragedQuantity
from yt.mods import *
# Load Data
pf = load('/home/skillman/kipac/data/enzo_cosmology_plus/DD0046/DD0046')
# Create a sphere with radius = 1/2 domain width
sp = pf.h.sphere(pf.domain_center, pf.domain_width[0]/2.)
# Calculate the average temperature
avg_T = sp.quantities['WeightedAverageQuantity']('Temperature', 'Density')
print avg_T
% mpirun -np 4 python avg_quantity.py --parallel
5435354.41045
5435354.41045
5435354.41045
5435354.41045
Non-trivial Parallization
Projections (Parallel Quad-Tree)
Slices (Slice Plots)
Cutting planes (oblique slices) (Off Axis Slice Plots)
Derived Quantities (total mass, angular momentum, etc) (Creating Derived Quantities, Processing Objects: Derived Quantities)
1-, 2-, and 3-D profiles (Profiles and Histograms)
Halo finding (Halo Finding)
Merger tree (Halo Merger Tree)
Two point functions (Two Point Functions)
Volume rendering (Volume Rendering)
Radial column density (Radial Column Density)
Isocontours & flux calculations (Extracting Isocontour Information)
In-Situ Analysis, c/o Britton Smith, MSU
Case Study: Volume Rendering
Three Levels:
Domain Decomposition (MPI)
Image Plane Decomposition (MPI)
Pixel Paralellization (OpenMP)
Domain Decomposition
Parallel AMR kd-tree Domain Decomposition
- Decomposes into single-resolution bricks
- Unique ordered traversal
- Straightforward parallel compositing
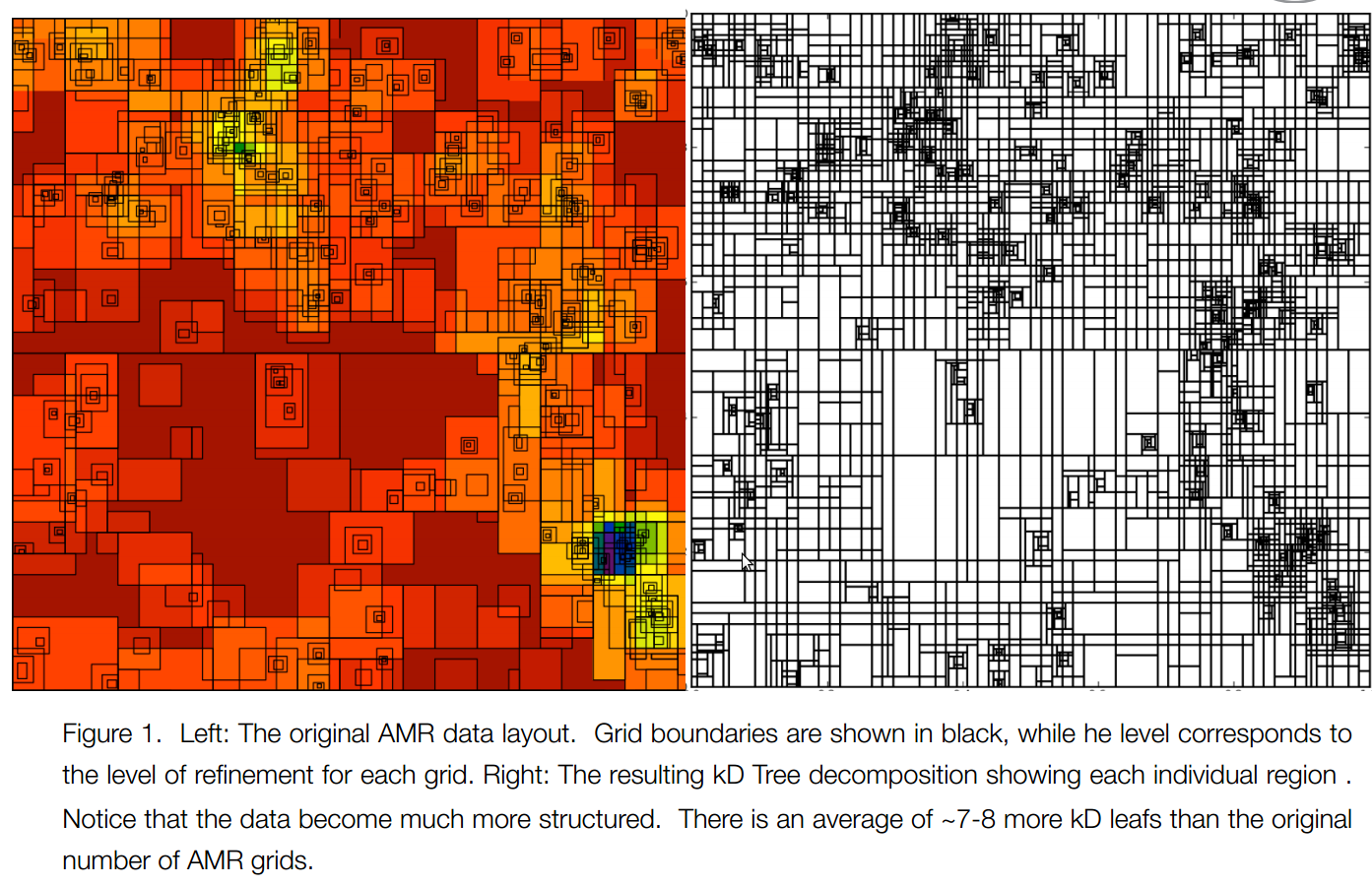
level # grids # cells # cells^3
----------------------------------------------
0 512 1073741824 1023
1 39444 571962944 830
2 2736 21966136 280
3 683 5150000 172
4 292 2088144 127
----------------------------------------------
43667 1674909048
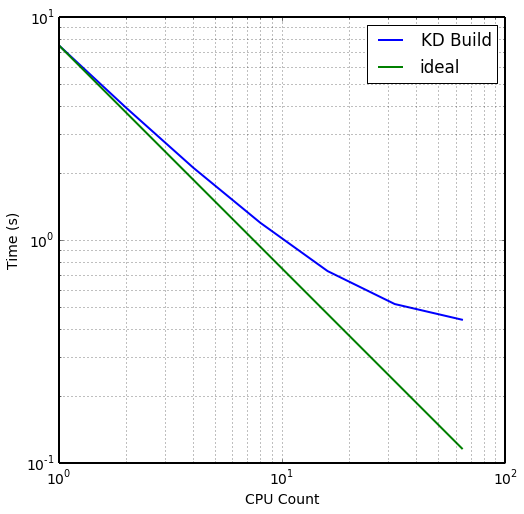
Image Plane Decomp
- Split N/M pixel image into P/Q panels
- Useful for Large (>2048^2) pixel canvas
- Incures non-trivial overlap conditions with parallel decomposition
- Memory-effiecient image planes. Final image composited in post-processing
Pixel Parallelization
- Given Intersection of Image plane with Brick of Data
- N pixels intersect
- OpenMP Loop in Cython
- Best where the size of a brick is large compared to image plane
Showcase
3200^3 Simulation of Re-ionization
Credit: Michael Norman, Robert Harkness, Daniel Reynolds, Geoffrey So
Each field is 244 GB
16 Nodes, 2 MPI x 8 OpenMP, 256 Total Workers
300 seconds to read in
15s/frame 1024^2 images, 35s/frame for 4096^2
This frame may not show up.